

SAN FRANCISCO — Meta is facing accusations of manipulating AI benchmarks after it emerged that the version of its Llama 4 Maverick model tested on the popular AI benchmark site LMArena was not the same as the one released to the public. The revelation has sparked concerns about the integrity of AI benchmarking and the potential for companies to “game the system.”
In a press release announcing the release of its new Llama 4 models, Meta touted Maverick’s impressive performance, claiming it outperformed industry leaders GPT-4o and Gemini 2.0 Flash “across a broad range of widely reported benchmarks.” The company emphasized Maverick’s high ELO score of 1417, which placed it above OpenAI’s GPT-4o and just under Google’s Gemini 2.5 Pro on LMArena.
However, AI researchers soon noticed discrepancies in Meta’s documentation. The version of Maverick that secured the second spot on LMArena’s leaderboard was not the publicly available model but an “experimental chat version” specifically “optimized for conversationality,” as reported by TechCrunch.
LMArena, which prides itself on providing fair and reproducible evaluations, quickly addressed the issue. “Meta’s interpretation of our policy did not align with our expectations,” the site posted on X two days after Maverick’s release. “They should have made it clearer that ‘Llama-4-Maverick-03-26-Experimental’ was a customized model optimized for human preference.”
In response, LMArena announced it would update its leaderboard policies to ensure that all models submitted for testing are representative of their public releases. This move aims to prevent future confusion and maintain the site’s commitment to transparency and fairness.
Meta defended its actions, stating that experimenting with different model variants is a common practice. “We experiment with all types of custom variants,” said Meta spokesperson Ashley Gabriel in an emailed statement. “‘Llama-4-Maverick-03-26-Experimental’ is a chat-optimized version we tested that also performed well on LMArena. We have now released our open-source version and are excited to see how developers customize Llama 4 for their own use cases.”
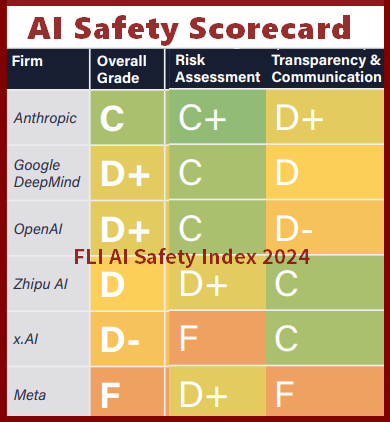
The incident has raised important questions about the reliability of AI benchmarks. When companies can submit specially-tuned versions of their models for testing while releasing different versions to the public, benchmark rankings may not accurately reflect real-world performance.
LMArena has previously expressed concerns about “gaming the system” and has implemented measures to “prevent overfitting and benchmark leakage.” Overfitting occurs when a model performs exceptionally well on a specific test set but fails to generalize to new data. Benchmark leakage refers to the unintentional sharing of information that could give a model an unfair advantage.
The Maverick incident underscores the challenges of evaluating AI models in a rapidly evolving field. As AI technology continues to advance, the need for clear and transparent benchmarking practices becomes increasingly important. Companies must ensure that the models they submit for testing are representative of what they release to the public.
For now, Meta’s Llama 4 Maverick stands as a testament to the company’s ambition and technical expertise. However, as AI researchers and users seek to understand the true capabilities of these models remains in question.





{kind=link}